Google Search Console is a free application that allows you to identify, troubleshoot, and resolve any issues that Google may encounter as it crawls and attempts to index your website in search results. It can also give you a window into which pages are ranking well, and which pages Google has chosen to ignore.
In the video below, we offer a quick high-level overview of the tool and reports Google Search Console provides:
One of the most powerful features of the tool is the Index Coverage Report. It shows you a list of all the pages on your site that Google tried to crawl and index, along with any issues it encountered along the way.
When Google is crawling your site, it means that your pages are being discovered and looked at to determine if their information is worthy of being indexed. Indexing means that those pages have been analyzed by Google's crawler ("Googlebot") and stored on index servers, making them eligible to come up for search engines queries.
If you’re not the most technical person in the world, some of the errors you’re likely to encounter there may leave you scratching your head. We wanted to make it a bit easier, so we put together this handy set of tips to guide you along the way. We’ll also explore both the Mobile Usability and Core Web Vitals reports.
Before we dive-in to each of the issues, here is a quick summary of what Google Search Console is, and how you can get started with it.
Getting Started With Search Console
Domain Verification
First things first: If you haven’t already done so, you’ll want to make sure you verify ownership of your website in Google Search Console. This step is one we highly suggest, as it allows you to see all of the subdomains that fall under your main site.
Be sure to verify all versions of your domain. This includes:
- http://yourdomain.com
- https://yourdomain.com
- http://www.yourdomain.com
- https://www.yourdomain.com
- And any other non-www subdomains including blog.yourdomain.com, info.yourdomain.com, etc.
Google treats each of these variations as a separate website, so if you do not verify each version, there’s a good chance you’ll miss out on some important information.
Navigating the Index Coverage Report
Once you’ve verified your website, navigate to the property you would like to start with.
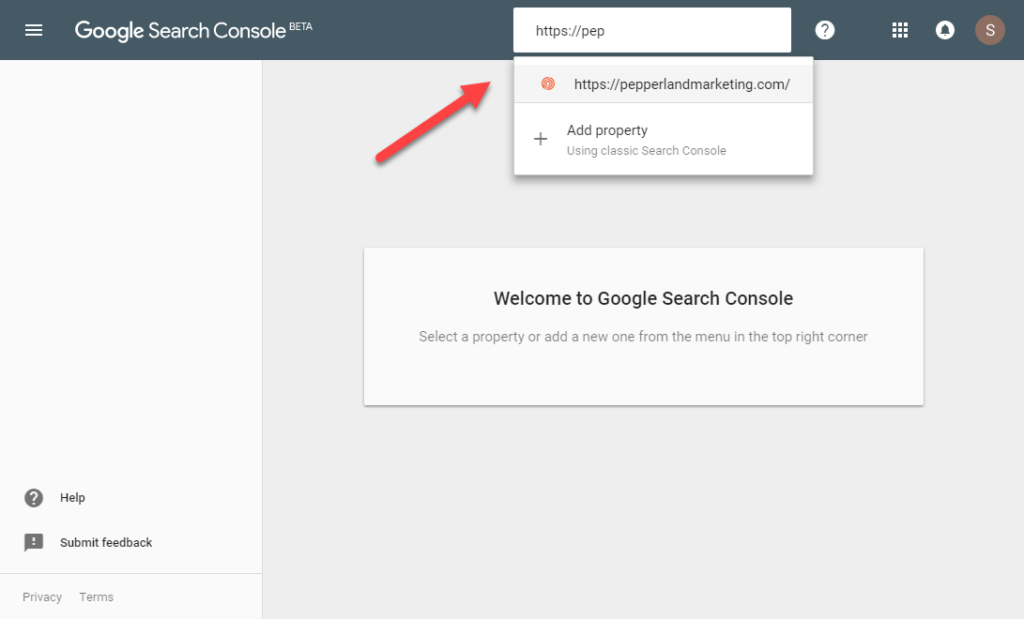
I recommend focusing on the primary version of your website first. That is, the version you see when you try visiting your website in your browser. Ultimately, though, you’ll want to review all versions.
Note: Many sites redirect users from one version to another, so there’s a good chance this is the only version Google will be able to crawl and index. Therefore, it will have the majority of issues for you to troubleshoot.
You’ll see a dashboard showing your trended performance in search results, index coverage, and enhancements. Click OPEN REPORT in the upper right-hand corner of the Index coverage chart.
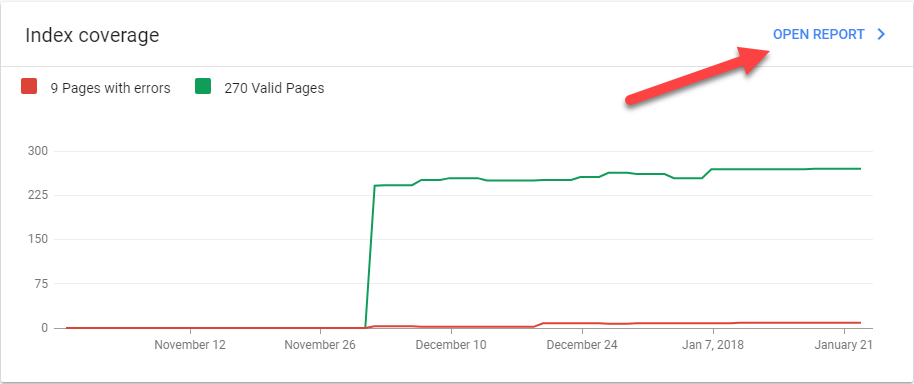
This is where you can do a dive-deep into all of the technical issues that are potentially preventing your website from ranking higher in search results. There are four types of issues: Error, Valid with warnings, Valid, and Excluded.

In the section below, we’ll walk through each of the potential issues you’re likely to find here in layman’s terms, and what you should do about them. The list comes from Google’s official documentation, which we strongly recommend reading as well.
Once you believe you have solved the issue, you should inform Google by following the issue resolution workflow that is built into the tool. We’ve outlined the steps for doing this towards the bottom of the article.
Are Google Search Console errors your only SEO issue? Download our 187 point self-audit checklist!
Google Search Console Errors List
If Google’s crawler, Googlebot, encounters an issue when it tries to crawl your site and doesn't understand a page on your website, it’s going to give up and move on. This means your page will not be indexed and will not be visible to searchers, which greatly affects your search performance.
Here are some of those errors:
- Server Error (5xx)
- Redirect Error
- Blocked by robots.txt
- Marked 'noindex'
- Soft 404
- Unauthorized request (401)
- Not Found (404)
- Crawl Issue
Focusing your efforts here is a great place to start.
How To Fix A Server error (5xx):
Your server returned a 500-level error when the page was requested.
A 500 error means that something has gone wrong with a website’s server that prevented it from fulfilling your request. In this case, something with your server prevented Google from loading the page.
First, check the page in your browser and see if you’re able to load it. If you can, there’s a good chance the issue has resolved itself, but you’ll want to confirm.
Email your IT team or hosting company and ask if the server has experienced any outages in recent days, or if there’s a configuration that might be blocking Googlebot and other crawlers from accessing the site.
How To Fix A Redirect error:
The URL was a redirect error. Could be one of the following types: it was a redirect chain that was too long; it was a redirect loop; the redirect URL eventually exceeded the max URL length; there was a bad or empty URL in the redirect chain.
This basically means your redirect doesn’t work. Go fix it!
A common scenario is that your primary URL has changed a few times, so there are redirects that redirect to redirects. Example: http://yourdomain.com redirects to http://www.yourdomain.com which then redirects to https://www.yourdomain.com.
Google has to crawl a ton of content, so it doesn’t like wasting time and effort crawling these types of links. Solve this by ensuring your redirect goes directly to the final URL, eliminating all steps in the middle.
Submitted URL blocked by robots.txt:
You submitted this page for indexing, but the page is blocked by robots.txt. Try testing your page using the robots.txt tester.
There is a line of code in your robots.txt file that tells Google it’s not allowed to crawl this page, even though you’ve asked Google to do just that by submitting it to be indexed. If you do actually want it to be indexed, find and remove the line from your robots.txt file.
If you don’t, check your sitemap.xml file to see if the URL in question is listed there. If it is, remove it. Sometimes WordPress plugins will sneak pages into your sitemap file that don’t belong.
Submitted URL marked ‘noindex’:
You submitted this page for indexing, but the page has a ‘noindex’ directive either in a meta tag or HTTP response. If you want this page to be indexed, you must remove the tag or HTTP response.

You’re sending Google mixed signals. “Index me… no, DON’T!” Check your page’s source code and look for the word “noindex”. If you see it, go into your CMS and look for a setting that removes this, or find a way to modify the page’s code directly.
It’s also possible to noindex a page through an HTTP header response via an X-Robots-Tag, which is a bit trickier to spot if you’re not comfortable working with developer tools. You can read more about that here.
Submitted URL seems to be a Soft 404:
You submitted this page for indexing, but the server returned what seems to be a soft 404.

These are pages that look like they are broken to Google, but aren’t properly showing a 404 Not Found response. These tend to bubble up in two ways:
- You have a category page with no content within that category. It’s like an empty shelf at a grocery store.
- Your website’s theme is automatically creating pages that shouldn’t exist.
You should either convert these pages to proper 404 pages, redirect them to their new location, or populate them with some real content.
For more on this issue, be sure to read our in-depth guide to fixing Soft 404 errors.
Submitted URL returns unauthorized request (401):
You submitted this page for indexing, but Google got a 401 (not authorized) response. Either remove authorization requirements for this page, or else allow Googlebot to access your pages by verifying its identity.
This warning is usually triggered when Google attempts to crawl a page that is only accessible to a logged-in user. You don’t want Google wasting resources attempting to crawl these URLs, so you should try to find the location on your website where Google discovered the link, and remove it.
For this to be “submitted”, it would need to be included in your sitemap, so check there first.
Submitted URL not found (404):
You submitted a non-existent URL for indexing.
If you remove a page from your website but forget to remove it from your sitemap, you’re likely to see this error. This can be prevented from regular maintenance of your sitemap file.
Deep Dive Guide: For a closer look at how to fix this error, read our article about how to fix 404 errors on your website.
Submitted URL has crawl issue:
You submitted this page for indexing, and Google encountered an unspecified crawling error that doesn’t fall into any of the other reasons. Try debugging your page using the URL Inspection tool.

Something got in the way of Google’s ability to fully download and render the contents of your page. Try using the Fetch as Google tool as recommended, and look for discrepancies between what Google renders and what you see when you load the page in your browser.
If your page depends heavily on Javascript to load content, that could be the problem. Most search engines still ignore Javascript, and Google still isn’t perfect at it. A long page load time and blocked resources are other possible culprits.
Google Search Console Warnings List
Warnings aren’t quite as severe as errors but still require your attention. Google may or may not decide to index the content listed here, but you can increase the odds of your content being indexed, and potentially improve your rankings if you resolve the warnings that Google Search Console uncovers.
Indexed, though blocked by robots.txt:
The page was indexed, despite being blocked by robots.txt
Your robots.txt file is sort of like a traffic cop for search engines. It allows some crawlers to go through your site and blocks others. You can block crawlers at the domain level or on a page by page basis.
Unfortunately, this specific warning is something we see all the time. It usually happens when someone attempts to block a bad bot and puts in an overly strict rule.
Below is an example of a local music venue that we noticed was blocking all crawlers from accessing the site, including Google. Don’t worry, we let them know about it.

Blocked By Robots
Even though the website remained in search results, the snippet was less than optimal because Google was unable to see the Title Tag, Meta Description, or page content.
So, how do you fix this? Most of the time, this warning occurs when both of these are present: a disallow command in your robots.txt file and a noindex meta tag in the page’s HTML. You’ve used a noindex directive to tell search engines that a page should not be crawled, but you’ve also blocked crawlers from viewing these pages in your robots.txt file. If search engine crawlers can’t access these URLs, they can’t see the noindex directive.
To drop these URLs from the index and resolve the Indexed, though blocked by robots.txt warning, you’ll want to remove the disallow command for these URLs in your robots.txt file. Crawlers will then see the noindex directive and drop these pages from the index.
Google Search Console Valid URLs List
This tells you about the part of your site that is healthy. Google has successfully crawled and indexed the pages listed here. Even though these aren’t issues, we’ll still give you a quick rundown of what each status means.
Submitted and indexed:
You submitted the URL for indexing, and it was indexed.
You wanted the page indexed, so you told Google about it, and they totally dug it. You got what you wanted, so go pour yourself a glass of champagne and celebrate!
Indexed, not submitted in sitemap:
The URL was discovered by Google and indexed.
Google found these pages and decided to index them, but you didn’t make it as easy as you could have. Google and other search engines prefer that you tell them about the content you want to have indexed by including them in a sitemap. Doing so can potentially increase the frequency in which Google crawls your content, which may translate into higher rankings and more traffic.
Indexed; consider marking as canonical:
The URL was indexed. Because it has duplicate URLs, we recommend explicitly marking this URL as canonical.
A duplicate URL is an example of a page that is accessible through multiple variations even though it is the same page. Common examples include when a page is accessible both with and without a backslash, or with a file extension at the end. Something like yoursite.com/index.html and yoursite.com, which both lead to the same page.
These are bad for SEO because it dilutes any authority a page accumulates through external backlinks between the two versions. It also forces a search engine to waste its resources crawling multiple URLs for a single page and can make your analytics reporting pretty messy as well.
A canonical tag is a single line in your HTML that tells search engines which version of the URL they should prioritize, and consolidates all link signals to that version. They can be extremely beneficial to have and should be considered.
Google Search Console Excluded URLs
These are the pages that Google discovered, but chose to not index. For the most part, these will be pages that you explicitly told Google not to index. Others are pages that you might actually want to have indexed, but Google chose to ignore them because they weren’t found to be valuable enough.
Blocked by ‘noindex’ tag:
When Google tried to index the page it encountered a ‘noindex’ directive, and therefore did not index it. If you do not want the page indexed, you have done so correctly. If you do want this page to be indexed, you should remove that ‘noindex’ directive.
This one is pretty straightforward. If you actually wanted this page indexed, they tell you exactly what you should do.
If you didn’t want the page indexed, then no action is required, but you might want to think about preventing Google from crawling the page in the first place by removing any internal links. This would prevent search engines from wasting resources on a page they shouldn’t spend time with, and focus more on pages that they should.
Blocked by page removal tool:
The page is currently blocked by a URL removal request.
Someone at your company directly asked Google to remove this page using their page removal tool. This is temporary, so consider deleting the page and allowing it to return a 404 error, or requiring a log-in to access if you wish to keep it blocked. Otherwise, Google may choose to index it again.
Blocked by robots.txt:
This page was blocked to Googlebot with a robots.txt file.
If a page is indexed in search results, but then suddenly gets blocked with a robots.txt file, Google will typically keep the page in the index for a period of time. This is because many pages are blocked accidentally, and Google prefers the noindex directive as the best signal as to whether or not you want content excluded.
If the blockage remains for too long, Google will drop the page. This is likely because they will not be able to generate useful search snippets for your site if they cannot crawl it, which isn’t good for anyone.
Blocked due to unauthorized request (401):
The page was blocked to Googlebot by a request for authorization (401 response). If you do want Googlebot to be able to crawl this page, either remove authorization requirements or allow Googlebot to access your pages by verifying its identity.
A common mistake is to link to pages on a staging site (staging.yoursite.com, or beta.yoursite.com,) while a site is still being built but then forgetting to update those links once the site goes live in production.
Search your site for these URLs, and fix them. You may need help from your IT team to do this if you have a lot of pages on your site. Crawling tools like Screamingfrog SEO Spider can help you scan your site in bulk.
Crawl anomaly:
An unspecified anomaly occurred when fetching this URL. This could mean a 4xx- or 5xx-level response code.
This issue may be a sign of a prolonged issue with your server. See if the page is accessible in your browser, and try using the URL Inspection tool. You may want to check with your hosting company to confirm there aren’t any major issues with the stability of your site.
In diagnosing this issue on many websites, we’ve found that the URLs in question are often:
- A part of a redirect chain
- A page that redirects to a page that returns a 404 error
- A page that no longer exists, and is returning a 404
If there’s something funny going on with your redirects, you should clean that up. Make sure there is only one step in the redirect and that the page your URL is pointing to loads correctly and returns a 200 response. Once you’ve fixed the issue, be sure to go back and fetch as Google so your content will be recrawled and hopefully indexed.
If the page returns a 404, make sure you’re not having page speed or server issues.
Crawled – currently not indexed:
The page was crawled by Google, but not indexed. It may or may not be indexed in the future; no need to resubmit this URL for crawling.
If you see this, take a good hard look at your content. Does it answer the searcher’s query? Is the content accurate? Are you offering a good experience for your users? Are you linking to reputable sources? Is anyone else linking to it?
Make sure to provide a detailed framework of all the page content that needs to be indexed through the use of structured data. This allows search engines to not only index your content but for it to come up in future queries and possible featured snippets.
Optimizing the page may increase the chances that Google chooses to index it the next time it is crawled.
Related: Why Isn’t My Content Indexed? 4 Questions To Ask Yourself
Discovered – currently not indexed:
The page was found by Google, but not crawled yet.
Even though Google discovered the URL it did not feel it was important enough to spend time crawling. If you want this page to receive organic search traffic, consider linking to it more from within your own website. Be sure to promote this content to others with the hope that you can earn backlinks from external websites. External links to your content is a signal to Google that a page is valuable and considered to be trustworthy, which increases the odds of it being indexed.
Alternate page with proper canonical tag:
This page is a duplicate of a page that Google recognizes as canonical, and it correctly points to that canonical page, so nothing for you to do here!
Just as the tool says, there’s really nothing to do here. If it bothers you that the same page is accessible through more than one URL, see if there is a way to consolidate.
Duplicate without user-selected canonical::
This page has duplicates, none of which is marked canonical. We think this page is not the canonical one. You should explicitly mark the canonical for this page.
Google is guessing which page you want them to index. Don’t make it guess. You can explicitly tell Google which version of a page should be indexed using a canonical tag.
Duplicate non-HTML page:
A non-HTML page (for example, a PDF file) is a duplicate of another page that Google has marked as canonical.
Google discovered a PDF on your site that contained the same information as a normal HTML page, so they chose to only index the HTML version. Generally, this is what you want to happen, so no action should be necessary unless for some reason you prefer they use the PDF version instead.
Duplicate, Google chose different canonical than user:
This URL is marked as canonical for a set of pages, but Google thinks another URL makes a better canonical.
Google disagrees with you on which version of a page they should be indexing. The best thing you can do is make sure that you have canonical tags on all duplicate pages, that those canonicals are consistent, and that you’re only linking to your canonical internally. Try to avoid sending mixed signals.
We’ve seen this happen when a website specifies one version of a page as the canonical, but then redirects the user to a different version. Since Google cannot access the version you have specified, it assumes perhaps that you’ve made an error, and overrides your directive.
Not found (404):
This page returned a 404 error when requested. The URL was discovered by Google without any explicit request to be crawled.
Not found errors occur when Google tries to crawl a link or previously indexed URL to a page that no longer exists. Many 404 errors on the web are created when a website changes its links, but forgets to set up redirects from the old version to the new URL.
If a replacement for the page that triggers the 404 error exists on your website, you should create a 301 permanent redirect from the old URL to the new URL. This prevents Google, and your users, from seeing the 404 page and experiencing a broken link. It can also help you maintain the majority of any search traffic that had been going to the old page.
If the page no longer exists, continue to let the URL return a 404 error, but try to eliminate any links to it. Nobody likes broken links.
Page removed because of legal complaint:
The page was removed from the index because of a legal complaint.
If your website has been hacked and infected with malicious code, there’s a good chance you’ll see a whole lot of these issues bubbling up in your reports. Hackers love to create pages for illegal movie torrent downloads and prescription drugs, which legal departments at large corporations search for and file complaints against.
If you receive one of these, immediately remove the copyrighted material and make sure your website hasn’t been hacked. Be sure that all plugins are up to date, that your passwords are secure, and that you’re using the latest version of your CMS software.
Page with redirect:
The URL is a redirect, and therefore was not added to the index.
Google will only index URLs that return a 200 success status. If you're seeing this notice, it means that the URL is returning a redirect status code, such as a 301 or a 302. This makes it ineligible for indexation.
To resolve this, you need to determine if the issue is that the URL is redirecting, or if the issue is that you're leading Google to crawl a redirecting URL. If the issue is that the URL is redirecting, consider removing the redirect.
If the issue is that you're leading Google to crawl a redirecting URL, where you find this issue in your reports will have a big influence in how you pursue a fix.
If in the All submitted pages section:
This means the page with redirect was found in your submitted sitemap.xml file. Inclusion of a redirecting URL in your submitted sitemap.xml may be the true problem, rather than the fact that the URL is redirecting. This could be the result of a redirect being created before first unpublishing a page that was no longer needed. You can correct this situation by unpublishing the page in your CMS, and removing the URL from your sitemap.xml. The act of unpublishing is often enough to remove the page from your sitemap file, but your CMS and website might act differently, so you'll want to confirm.
If in the Unsubmitted pages only section:
This means that Google discovered the URL while crawling your website's hyperlinks, or when crawling an external site's hyperlinks. Externally, there is nothing that you can do. Internally, you may be able to take some action.
If you have hyperlinks pointing to the redirected URL on your website, you should consider replacing those hyperlinks with a URL that returns a 200 status. In the case of a redirect, this is usually the destination URL. Your goal should be to only link to valid 200-status URLs on your website.
Deep-Dive Guide: For more about best practices for redirects: Website Redirect SEO: 7 Self-Audit Questions
When to validate
You should only submit a validation request if you determined that the issue was that the URL was redirecting, and you've taken action to remove the redirect, allowing the URL to return a 200 status.
If you determined that the true problem was that you were leading Google to crawl a redirecting URL, you should pursue a fix as outlined above, but avoid submitting a validation request.
Queued for crawling:
The page is in the crawling queue; check back in a few days to see if it has been crawled.
This is good news! Expect to see your content indexed in search results soon. Go microwave a bag of popcorn and check back in a little bit. Use this downtime to clean up all of the other pesky issues you’ve identified in the Index Coverage report.
Soft 404:
The page request returns what we think is a soft 404 response.
In Google’s eyes, these pages are a shell of their former selves. The remnants of something useful that once existed, but no longer does. You should convert these into 404 pages, or start populating them with useful content.
Submitted URL dropped:
You submitted this page for indexing, but it was dropped from the index for an unspecified reason.
This issue ‘s description is pretty vague, so it’s hard to say with certainty what action you should take. Our best guess is that Google looked at your content, tried it out for a while, then decided to no longer include it.
Investigate the page and critique its overall quality. Is the page thin? Outdated? Inaccurate? Slow to load? Has it been neglected for years? Have your competitors put out something that’s infinitely better?
Try refreshing and improving the content, and secure a few new links to the page. It may lead to a re-indexation of the page.
Duplicate, Submitted URL not selected as canonical:
The URL is one of a set of duplicate URLs without an explicitly marked canonical page. You explicitly asked this URL to be indexed, but because it is a duplicate, and Google thinks that another URL is a better candidate for canonical, Google did not index this URL. Instead, we indexed the canonical that we selected.

Google crawled a URL that you explicitly asked it to, but then you also told Google a duplicate of the page was actually the one it should index and pay attention to.
Decide which version you want to have indexed, set it as the canonical, and then try to give preference to that version when linking to a page in the set of duplicates both internally on your own website and externally.
How To Navigate the Mobile Usability Report
As more and more of the web’s traffic and daily searches occur on mobile devices, Google and other search engines have given increased focus on the importance of mobile usability when determining a page’s rankings.
The Mobile Usability report in Google Search Console helps you quickly identify mobile-friendliness issues that could be hurting your user’s experience and holding your website back from obtaining more organic traffic.
In the section below we walk through some of the most common issues detected in this report, and how you might work to resolve them.
When your page uses incompatible plugins
The page includes plugins, such as Flash, that are not supported by most mobile browsers. We recommend designing your look and feel and page animations using modern web technologies.
In 2017, Adobe announced it would stop supporting Flash by the end of 2020. This was one of the final nails in the coffin of Flash, which wasn’t mobile-friendly and plagued with security issues. Today, there are better open web technologies that are faster and more power-efficient than Flash.
To fix this issue, you’ll either need to replace your Flash element with a modern solution like HTML5, or remove the content altogether.
Viewport not set
The page does not define a viewport property, which tells browsers how to adjust the page’s dimension and scaling to suit the screen size. Because visitors to your site use a variety of devices with varying screen sizes—from large desktop monitors, to tablets and small smartphones—your pages should specify a viewport using the meta viewport tag.
The “viewport” is the technical way that your browser knows how to properly scale images and other elements of your website so that it looks great on all devices. Unless your HTML savvy, this will likely require the help of a developer. If you want to take a stab at it, this guide might be helpful.
Viewport not set to “device-width”
The page defines a fixed-width viewport property, which means that it can’t adjust for different screen sizes. To fix this error, adopt a responsive design for your site’s pages, and set the viewport to match the device’s width and scale accordingly.
In the early days of responsive-design, some developers preferred to tweak the website for mobile-experiences rather than making the website fully responsive. The fixed-width viewport is a great way to do this, but as more and more mobile devices enter the market, this solution is less appealing.
Google now favors responsive web experiences. If you’re seeing this issue, it’s likely that you’re frustrating some of your mobile users, and potentially losing out on some organic traffic. It may be time to call an agency or hire a developer to make your website responsive.
Content wider than screen
Horizontal scrolling is necessary to see words and images on the pageThis happens when pages use absolute values in CSS declarations, or use images designed to look best at a specific browser width (such as 980px). To fix this error, make sure the pages use relative width and position values for CSS elements, and make sure images can scale as well.
This usually occurs when there is a single image or element on your page that isn’t sizing correctly for mobile devices. In WordPress, this can commonly occur when an image is given a caption or a plug-in is used to generate an element that isn’t native to your theme.
The easy way to fix this issue is to simply remove the image or element that is not sizing correctly on mobile devices. The correct way to fix it is to modify your code to make the element responsive.
Text too small to read
The font size for the page is too small to be legible and would require mobile visitors to “pinch to zoom” in order to read. After specifying a viewport for your web pages, set your font sizes to scale properly within the viewport.
Simply put, your website is too hard to read on mobile devices. To experience this first-hand, simply load the page in question on a smartphone and experience it first hand.
According to Google, a good rule of thumb is to have the page display no more than 70 to 80 characters (about 8-10 words) per line on a mobile device. If you’re seeing more than this, you should hire an agency or developer to modify your code.
Clickable elements too close together
This report shows the URLs for sites where touch elements, such as buttons and navigational links, are so close to each other that a mobile user cannot easily tap a desired element with their finger without also tapping a neighboring element. To fix these errors, make sure to correctly size and space buttons and navigational links to be suitable for your mobile visitors.
Ever visit a non-responsive website that had links so small that it was IMPOSSIBLE to use? That’s what this issue is all about. To see the issue first-hand, try loading the page on a mobile device and click around as though you were one of your customers. If it’s hard to navigate from one page to another, and the experience requires you to zoom in before you click, you can be sure that you have a problem.
Google recommends that clickable elements have a targeted touch size of about 48 pixels, which is usually about 1/3 of the width of a screen, or about the size of a person’s finger pad. Consider replacing small text links with large buttons as an easy solution.
How To Navigate the Core Web Vitals Report
It’s important that you identify and fix any issues that may interfere with Google’s ability to crawl and rank your website, but Google also takes into account whether your website provides a good user experience.
The Core Web Vitals report in Google Search Console zeroes in on page speed. It focuses on key page speed metrics that measure the quality of the user experience so that you can easily identify any opportunities for improvement and make the necessary changes to your site.
For all of the URLs on your site, the report displays three metrics (LCP, FID, and CLS) and a status (Poor, Needs Improvement, or Good).
Here are Google’s parameters for determining the status of each metric.
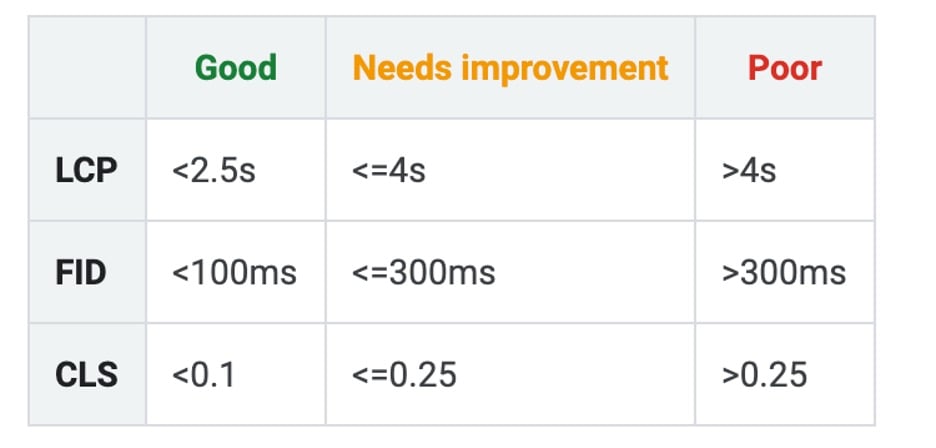
Let’s take a look at each of the three metrics, and how to improve each one.
- Largest Contentful Paint (LCP): The amount of time it takes to display the page’s largest content element to the user after opening the URL
- First Input Delay (FID): The amount of time it takes for the browser to respond to an interaction (like clicking a link) by the user
- Cumulative Layout Shift (CLS): A measure of how often the layout of your site changes unexpectedly, resulting in a poor user experience
Largest Contentful Paint (LCP)
Largest Contentful Paint (LCP) refers to the amount of time it takes to display the page’s largest content element to the user after opening the page. If the main element fails to load within a reasonable amount of time (under 2.5s), this contributes to a poor user experience seeing that nothing is populating on-screen.
First Input Delay (FID)
First Input Delay (FID) is a measure of how long it takes for the browser to respond to an interaction by the user (like clicking a link, etc.). This is a valuable metric as it’s a direct representation of how responsive your website is. A user is likely to become frustrated if interactive elements on a page take too long to respond.
Cumulative Layout Shift (CLS)
Cumulative Layout Shift (CLS) is a measure of how often the layout of your site changes unexpectedly during the loading phase. CLS is important because layout changes that occur while a user is attempting to interact with a page can be incredibly frustrating and result in a poor user experience.
Improving Core Web Vitals
A simple way to check these metrics on the page-level and quickly identify fixes is to utilize Chrome DevTools.
After identifying a page with an issue within Google Search Console, navigate to that page URL and press Control+Shift+C (Windows) or Command+Shift+C (Mac). Alternatively, you can right-click anywhere on the page and click on “Inspect.”
From there, you’ll want to navigate to the “Lighthouse” menu option.
Lighthouse will audit the page and generate a report, scoring the performance of the page out of 100. You’ll find measurements for LCP, FID, and CLS, in addition to other helpful page speed metrics.
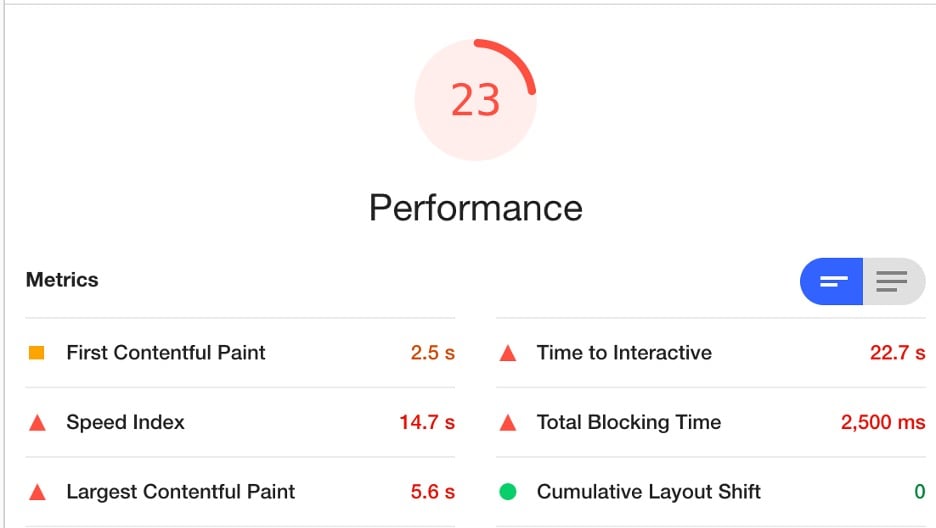
The best part of Google Lighthouse is that it provides actionable recommendations for improving the above metrics, along with the Estimated Savings.
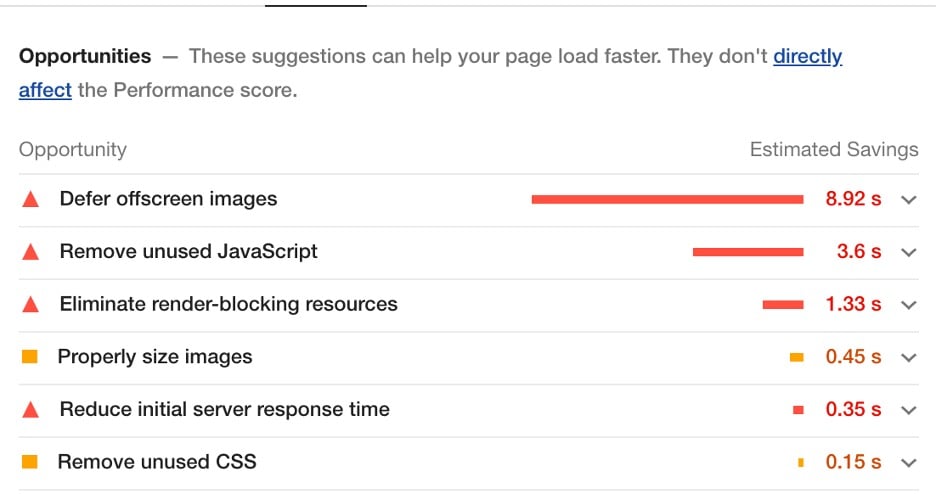
Work with your developer to implement the recommended changes where possible.
How To Tell Google You’ve Fixed An Issue
As you navigate through each issue, you’ll notice that clicking on a page’s URL will open a new panel on the right side of your screen.
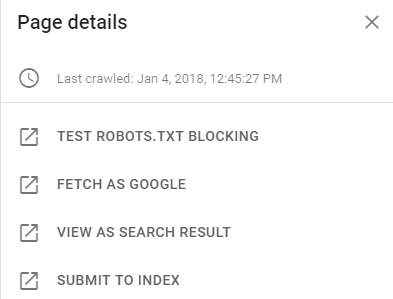
Go through this list and make sure you’re happy with what you see. Google put these links here for a reason: they want you to use them.
If you’re still confident the issue is resolved, you can finish the process by clicking VALIDATE FIX.
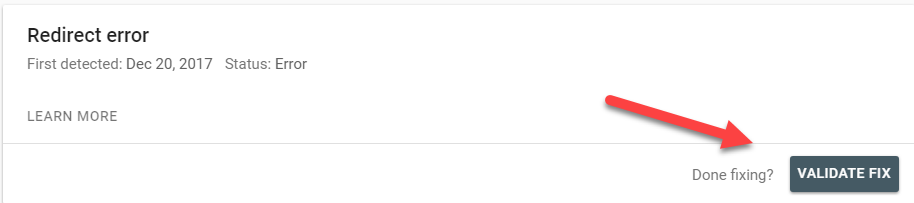
At this point, you’ll receive an email from Google that lets you know the validation process has begun. This will take several days to several weeks, depending on the number of issues Google needs to re-crawl.
If the issue is resolved, there’s a good chance that your content will get indexed and you’ll start to show up in Google search results. This means a greater chance to drive organic search traffic to your site. Woohoo! You’re a search-engine-optimization superhero!