If you’re overseeing your company’s technical SEO efforts or you’re tasked with growing traffic to a website, Google Search Console is one of the most valuable tools that you can use to glean insights about your website’s health.
Within Google Search Console, the Index Coverage Report gives you a detailed view of which pages on your site have been indexed and alerts you of any indexing issues that Googlebot encountered while crawling your site.
If Google does come across any indexing issues, (which you’ll find in the ‘Errors’ and ‘Warnings’ sections of the Coverage Report) you’ll want to fix them immediately to ensure that your content is being indexed correctly and is ranking in search results.
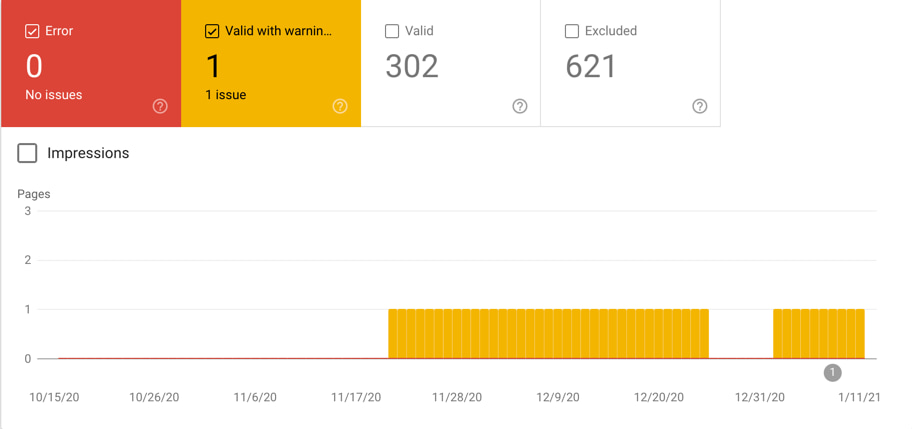
A common warning that you might come across in the Coverage Report is titled “Indexed, though blocked by robots.txt.”
Here, we explain what this message means and provide step-by-step instructions for fixing it.
What does the “Indexed, though blocked by robots.txt” warning mean?
According to Google, this warning indicates that the URL in question was indexed at one point but is now being blocked by the robots.txt file. This usually occurs when someone doesn’t want a page to be crawled any more and adds it to the robots file instead of adding a noindex directive to the page.
What is a robots.txt file?
Your robots.txt file is a text file that provides instructions to robots (search engine crawlers) regarding the pages on your site they should be crawling and those they should not. By “allowing” or “disallowing” the behavior of crawlers, you’re saying “Yes, crawl this page!” or “No, don’t crawl this page!”
To explain this further, let’s take a look at the robots.txt file for Walmart.com. In the photo below, we can see that Walmart is telling crawlers not to visit the URL “/account/” by using the disallow rule.
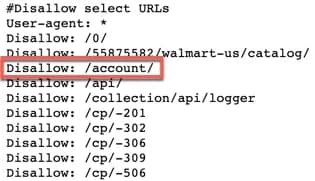
This also implies that since the robots are unable to crawl the page they shouldn’t be able to index it. However, this is not always the case.
Let’s see why this would happen.
What causes the “Indexed, though blocked by robots.txt” warning?
Assuming there are disallow rules in place for the URLs in question, you don’t want them to be indexed. So, why is this happening?
Most of the time, this warning occurs when both of the following are true:
- There is a disallow rule in the robots.txt file
- There is a noindex meta tag in the page’s HTML
In this scenario, you’re simultaneously telling Google not to crawl this page and not to index it. The problem here is that if you’ve blocked crawlers from viewing this page via the rule in your robots.txt, they won’t be able to see the noindex directive in the HTML and drop the page from the index.
Are there more errors on your site? Download our 187 point self-audit checklist!

While it may sound complicated, this warning is fairly simple to resolve.
How do you fix the “Indexed, though blocked by robots.txt” warning?
To fix the “Indexed, though blocked by robots.txt” warning, you’ll want to first make sure you have a noindex directive in place on the page you’re looking to remove from Google’s index. Then, you’ll want to remove the disallow rule from the robots.txt file to allow Google to see the noindex directive and subsequently drop the affected pages from the index.
The specific steps to do this vary depending on your CMS. Below, we’ll take a look at the steps to fix this warning for WordPress sites.
How to Edit Your Robots.txt File in WordPress
The easiest way to edit the robots.txt file for your WordPress is by using Yoast SEO. Simply follow the steps below:
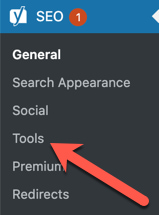
1. Navigate to Yoast from your WordPress dashboard and click on ‘Tools.’
2. Click on ‘File Editor.’
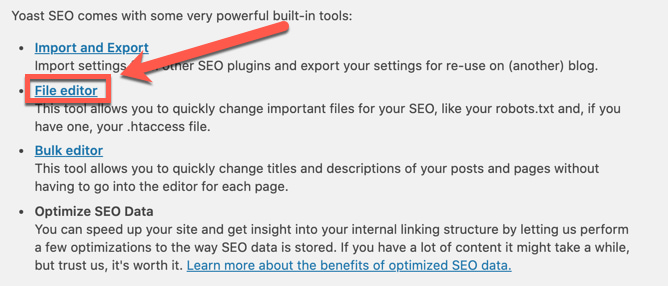
3. Edit the robots.txt and remove the disallow rules for the affected URL strings.
If you don’t have Yoast installed or your robots.txt is not in the File Editor, you can edit your robots.txt at the server level. We’ll dive into that soon.
How to Edit Your Robots.txt File Manually via FTP
For this option, you will need to access your server via FTP. You can do this with Adobe Dream Weaver and log in with your site’s credentials. Once you are connected to your server, follow the steps below:
- Download your robots.txt file from the server.
- Open the file with a plain text editor like Microsoft Notepad and remove the disallow rules for the affected URLs.
- Save the file without changing the name.
- Upload the file to the server, it will overwrite the old version of the robots.txt file.
Validating Your Fix in Google Search Console
Now that you’ve successfully updated your robots.txt file, you’re ready to tell Google!
To do this, navigate to the ‘Details’ section and click on the warning.
From here, you’ll simply click on ‘Validate Fix.’

Google will now recrawl the URLs, see the noindex directives, and drop the pages from the index. The warning should now be resolved, and you’re on your way to a healthy, SEO-friendly website!
This particular warning is just one of many crawl issues in Google Search Console that may threaten your website’s overall health. For a comprehensive list of errors on your website along with their solutions, contact us for a technical SEO audit and let us do the dirty work.






